Pioneer: 搭建数据引擎架构
Pioneer: 搭建数据引擎架构
Overview / The Challenge
2017年时,大麻行业尚处于起步阶段,市场碎片化且极不透明。品牌方和投资者几乎是在“盲飞”,缺乏像尼尔森(Nielsen)那样能验证营销表现的标准事实来源。
我创立 Pioneer Intelligence 是为了解决两个核心问题:
• 微观优化: 帮助运营商理解其特定策略、战术和信息在市场上的反馈。
• 宏观估值: 提供品牌健康度和品类相对实力的全景视图(30,000英尺视角)。
为了提供这种深度的洞察,我们不能简单地转售现有工具。我们必须构建一个专有引擎,能够从互联网的各种来源中提取并处理大量复杂的数据。
专业积淀: 工程师负责系统布线,而我负责架构逻辑。我确定了关键绩效指标(KPI),寻找数据源,并定义了权重模型。利用我的数字化背景,我设计了算法逻辑,使其能从虚荣指标(转瞬即逝的噪音)中识别出高价值信号(持久的品牌资产)。这种敏锐度确保了最终得分反映的是真实的业务影响力,而非机器人账号的虚假活跃。
策略思路 / 增长蓝图
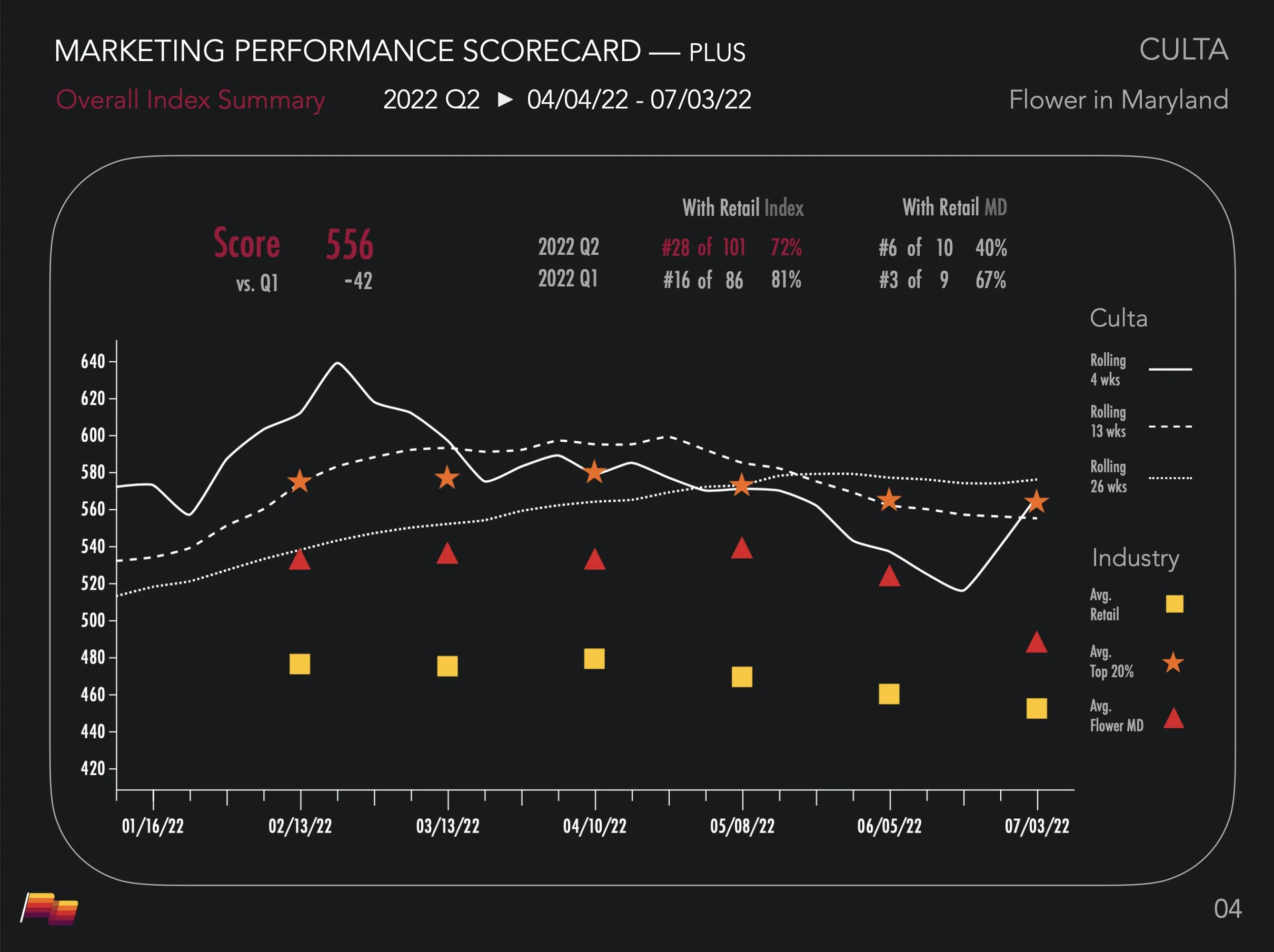
信号标准化。 我们的目标是将庞大且零散的数据流转化为标准化的定量指数。Pioneer Intelligence 衡量了社交媒体、赢得媒体和网站活跃度等维度的知名度与互动率,并将表现浓缩为两个维度:
• 热度(Heat,相对势能): 谁目前正在获胜?(变化速度)。
• 实力(Strength,绝对地位): 谁在品类中占据主导?(累积资产)。
数据洪流的运营化: 系统的左侧,定制的布尔架构充当“逻辑门”,严格过滤全球新闻以去伪存真;右侧,经过验证的数据被标准化并暂存,为核心引擎提供动力。
数据洪流的运营化: 系统左侧,定制的布尔架构充当“逻辑门”,严格过滤全球新闻以去伪存真;右侧,经过验证的数据被标准化并暂存,为核心引擎提供动力。
执行落地 / 体系构建
我设计了全栈 ETL(提取、转换、加载)流水线,编排了每周处理 100,000 多个数据点的自动化工作流:
• 摄取(Ingest): 我们构建了自动爬虫和 API 连接器,从 Meta、Meltwater、Ahrefs、SimilarWeb、SemRush 和 Weedmaps 等全平台抓取原始活跃数据。
• 标准化(CID 系统): 我们架构了一个核心规范品牌 ID(CID)层。它充当“通用翻译官”,将来自七个不同平台的混乱命名规则映射到统一的实体记录中。
• 清洗与异常检测: 我们编写算法自动标记异常情况——处理数据缺失周或抑制统计学异常值(如机器人驱动的流量激增),确保最终指数是由人类行为驱动,而非 API 错误。
• 评分引擎: 一个加权逻辑模型处理跨三个维度的 200 多个特征。至关重要的是,引擎会计算周环比、月环比和季环比变化,使我们能够隔离出“速度”指标,并在时间维度下理解表现。
• 自动发布: 流水线会自动将排名导出至我们的 WordPress 公开网站,并即时生成面向客户的评分卡(PDF)和面向分析师的 CSV 文件。
项目成果 / 数据表现
我们成功将一项手动的咨询任务转化为了可规模化的软件产品:
• 规模: 每周对 750 多个品牌进行基准测试,每次运行处理超过 10 万个数据点,且保持高可靠性。
• 产品化: Pioneer 指数成为行业标准,为运营方客户提供了一个衡量竞争对手营销效能的标准化标尺。
• 效率: 实现了“摄取 > 评分 > 发布”的闭环自动化,将原本需要分析师团队耗时数周的工作缩短为机器驱动的周级冲刺。


项目复盘 / 核心洞察
严谨造就公信力。 在一个碎片化、不透明的市场中,算法的价值取决于其背后的信任度。通过公开我们的具体方法论和维度定义,我们将一个“黑盒”转化为了透明的标准。文档的深度不仅仅是为了运营,它更是我们最强大的营销资产。